Setelah membahas Gradient Descent, kali ini akan dibahas mengenai Stochastic Gradient Descent (SGD). SGD sering dimanfaatkan dalam Neural Networks untuk meminimalkan error dalam mempelajari parameter.
Perbedaan SGD dengan Gradient Descent Secara
Penggunaan Gradient Descent dalam mencari optimum lokal dapat memboroskan waktu yang lama karena menggunakan semua data training. Sementara itu, SGD tidak menggunakan semua data training untuk menghitung gradien pada setiap iterasi. SGD hanya menggunakan satu atau beberapa bagian saja dari data training yang dipilih secara acak. Keuntungan dari SGD adalah tidak menggunakan memory sebanyak Gradient Descent sehingga bisa konvergen lebih cepat daripada Gradient Descent tradisional.
Kenapa demikian?
Misalkan kita memiliki data training berisi pasangan (xi, yi).
Diberikan sebuah fungsi h: X -> Y untuk memprediksi xi sehingga dihasilkan h(x) sebagai berikut
θi adalah parameter atau bobot dari fungsi yang ingin dicari nilainya. Sementara fungsi h(x) memperkirakan jika diberikan x = [x1, x2, ...., xn] akan dipetakan ke h(x). Maka h(x) dapat ditulis sebagai
Berikut adalah cost function untuk mengukur perbedaan h(x) dengan y sebagai berikut
Kenapa demikian?
Misalkan kita memiliki data training berisi pasangan (xi, yi).
Diberikan sebuah fungsi h: X -> Y untuk memprediksi xi sehingga dihasilkan h(x) sebagai berikut
h(x) = θ0 + θ1x1 + θ2x2 + ... + θnxn (1)
θi adalah parameter atau bobot dari fungsi yang ingin dicari nilainya. Sementara fungsi h(x) memperkirakan jika diberikan x = [x1, x2, ...., xn] akan dipetakan ke h(x). Maka h(x) dapat ditulis sebagai
h(x) = ∑θi xi (2)
Berikut adalah cost function untuk mengukur perbedaan h(x) dengan y sebagai berikut
J(θ) = 1/2 * ∑ (h(x) - y)^2 (3)
Perhatikan bahwa rumus (3) adalah cost function untuk estimasi least squares [4].
Secara umum, Gradient Descent didefinisikan sebagai berikut:

Jika dikerjakan, maka diperoleh penurunan berikut:
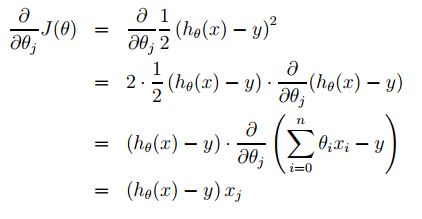
Sehingga ulangi terus persamaan berikut sampai konvergen untuk setiap J:
Rumus di atas berlaku untuk Gradient Descent biasa yang menggunakan semua contoh dalam data training untuk setiap iterasinya (juga disebut batch Gradient Descent).
Berbeda dari Gradient Descent, SGD hanya melihat 1 pasangan dalam 1 kali iterasinya. Jika ada m pasangan dalam data training, lakukan iterasi sebanyak m kali dengan hanya mengambil 1 contoh pada 1 iterasinya. Pseudocode SGD ditunjukkan sebagai berikut.

Tentu saja SGD lebih efisien daripada Gradient Descent jika ukuran m sangat besar.
Referensi:
Gradient Descent
ReplyDeletethanks for simple explanation, it will help me :)
ReplyDelete